Tesla V100 Gpu Review
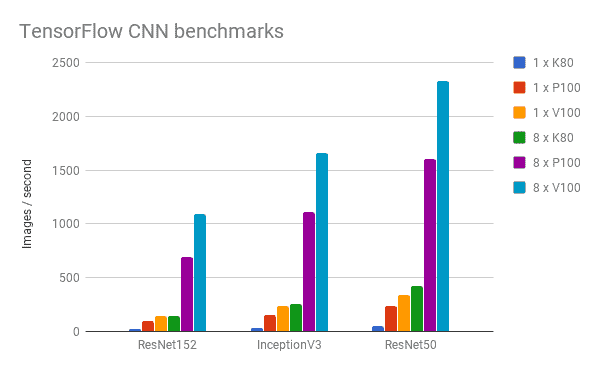
Nvidia Tesla V100 Benchmark Results On Rescale Rescale Resource Center
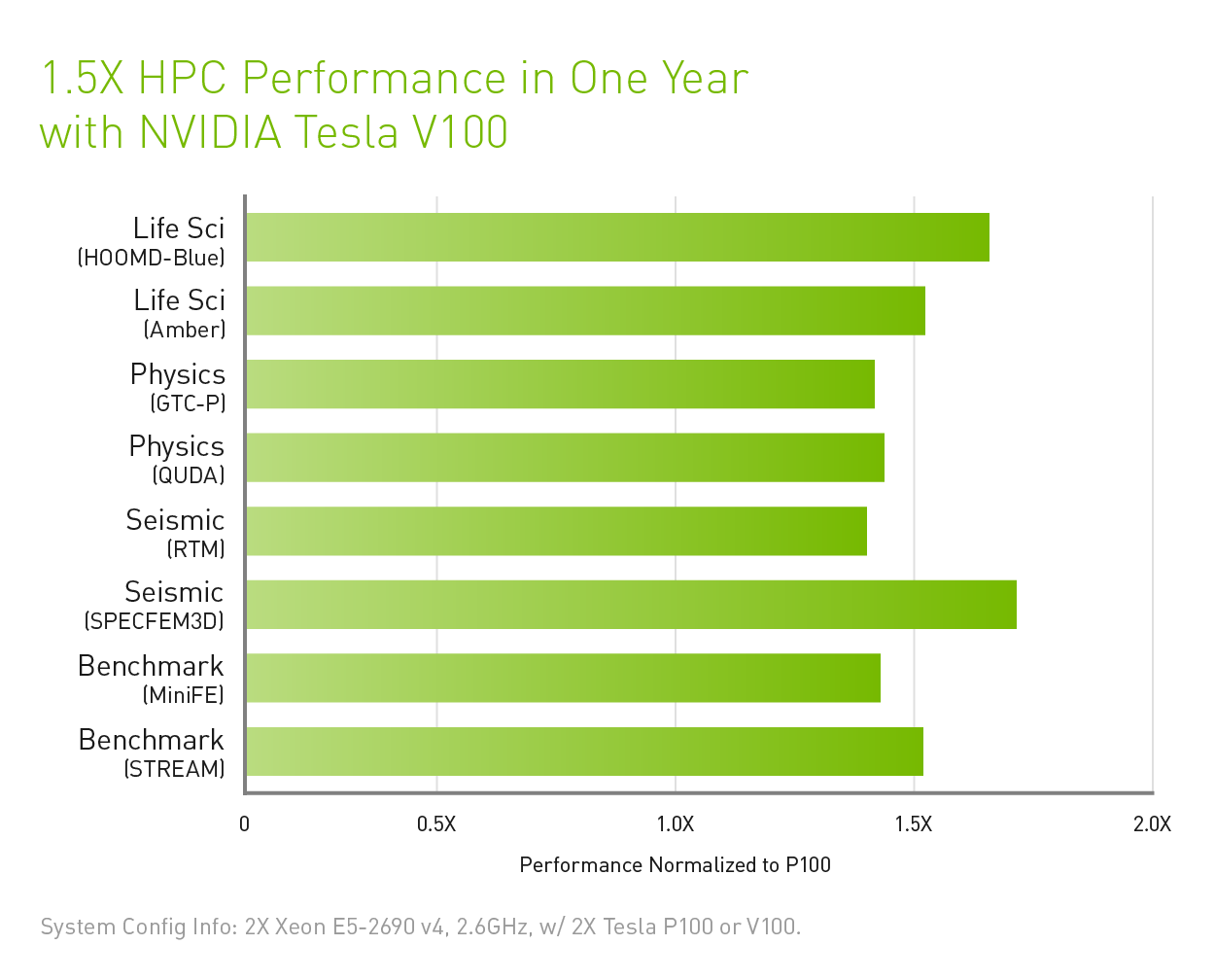
Nvidia Tesla V100 Price Analysis Microway
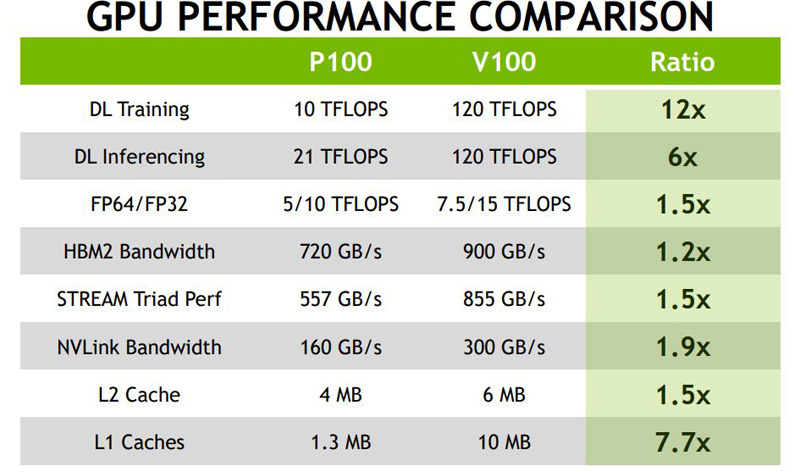
Nvidia Tesla V100 Tested Near Unbelievable Gpu Power Tweaktown
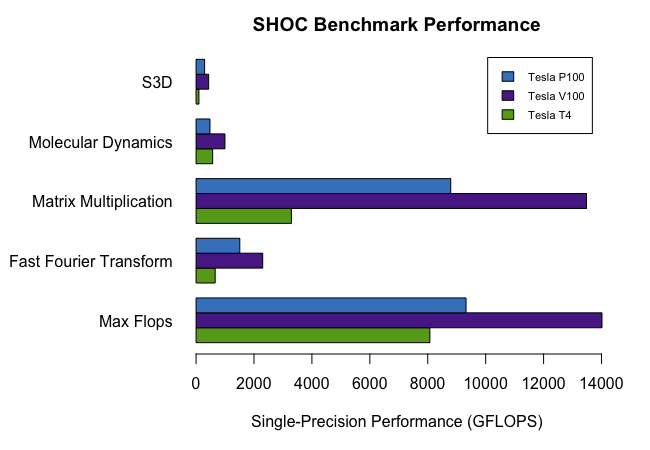
Comparison Of Tesla T4 P100 And V100 Benchmark Results Microway
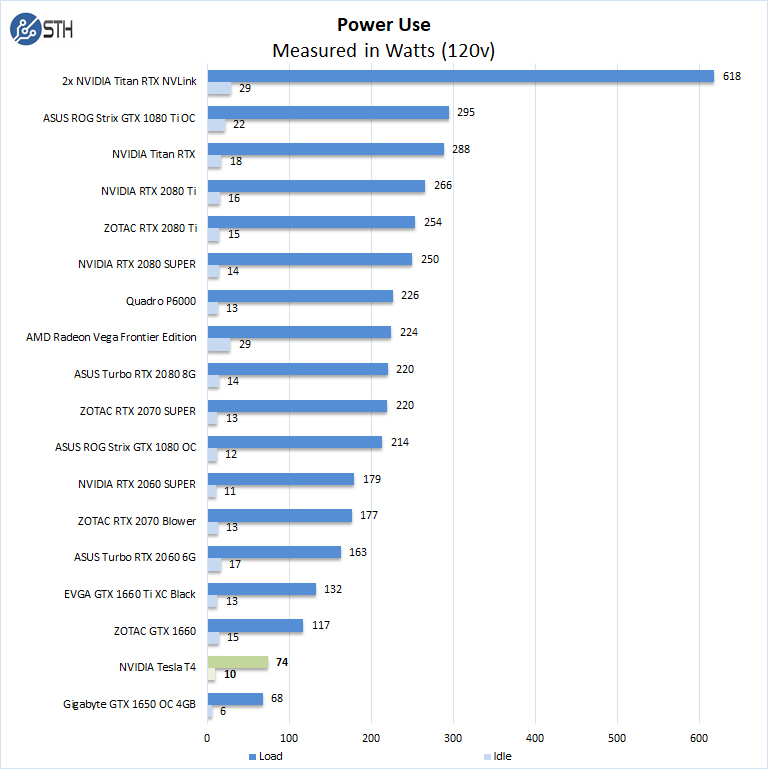
Nvidia Tesla T4 Ai Inferencing Gpu Benchmarks And Review Page 5 Of 5 Servethehome
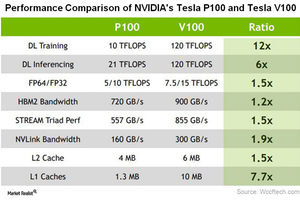
Reading The Third Party Reviews For Nvidia S Tesla V100 Gpu
The gpus are connected together using nvswitch technology which means each gpu has 300gb s of nvlink bandwidth to each of the other gpus.
Tesla v100 gpu review. Overall only 80 of 84 sms. News reviews articles guides gaming ask the experts newsletter forums. Whether your workload is in hpc ai or even remote visualization graphics acceleration tesla v100 has something for you. With it comes the new tesla v100 volta gpu the most advanced datacenter gpu ever built.
Being a dual slot card the nvidia tesla v100 sxm2 16 gb does not require any additional power connector its power draw is rated at 250 w maximum. Essentially this is half of an nvidia dgx 2 or hgx 2 in a 4u chassis. Nvidia tesla v100 tensor core is the most advanced data center gpu ever built to accelerate ai high performance computing hpc data science and graphics. Tesla v100 sxm2 16 gb is connected to the rest of the system using a pci express 3 0 x16 interface.
For the first time the beefy tesla v100 gpu is compelling for not just ai training but ai inference as well unlike tesla p100. Read honest and unbiased product reviews from our users. If your budget allows you to purchase at least 1 tesla v100 it s the right gpu to invest in for deep learning performance. Today i show you the mining hashrates of a 100 000 server from amazon with 8x nvidia nvlink tesla v100 gpu s on board.
This device has no display connectivity as it is not designed to have monitors connected to it. Volta gpu 16gb hbm2 900gb. Tesla v100 delivers a 6x on paper advancement. The result is the worlds fastest mine.
Not only is it using 8x tesla v100 sxm3 and for volta next gpus with 350w tdps but it has something special on the fabric side. Volta is nvidia s 2nd gpu architecture in 12 months and it builds upon the massive advancements of the pascal architecture. Read honest and unbiased product reviews from our users. Like its p100 predecessor this is a not quite fully enabled gv100 configuration.
Data scientists researchers and engineers can now spend less time optimizing memory usage and more time designing the next ai breakthrough.

Amd S Radeon Mi60 Ai Resnet Benchmark Had Nvidia Tesla V100 Gpu Operating Without Tensor Enabled
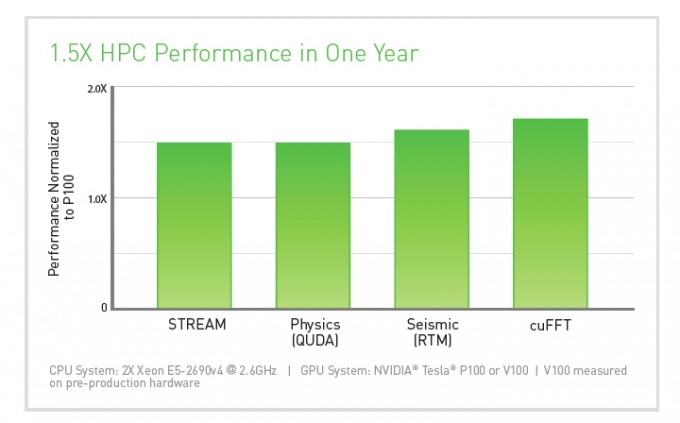
Tesla V100 Volta Gpu Review

Nvidia Tesla V100s Boasts Big Performance Gains At Same Power
What Is The Best Gpu For Deep Learning Nvidia Tesla K40 K80 M40 Or M60 Quora
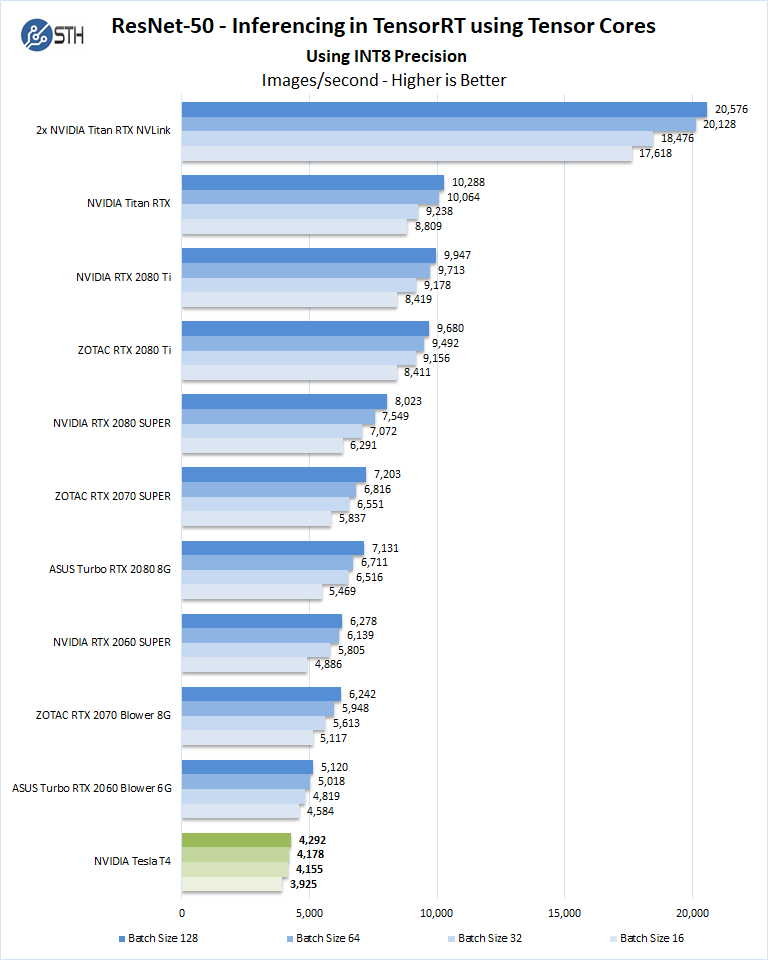
Nvidia Tesla T4 Ai Inferencing Gpu Benchmarks And Review Page 4 Of 5 Servethehome
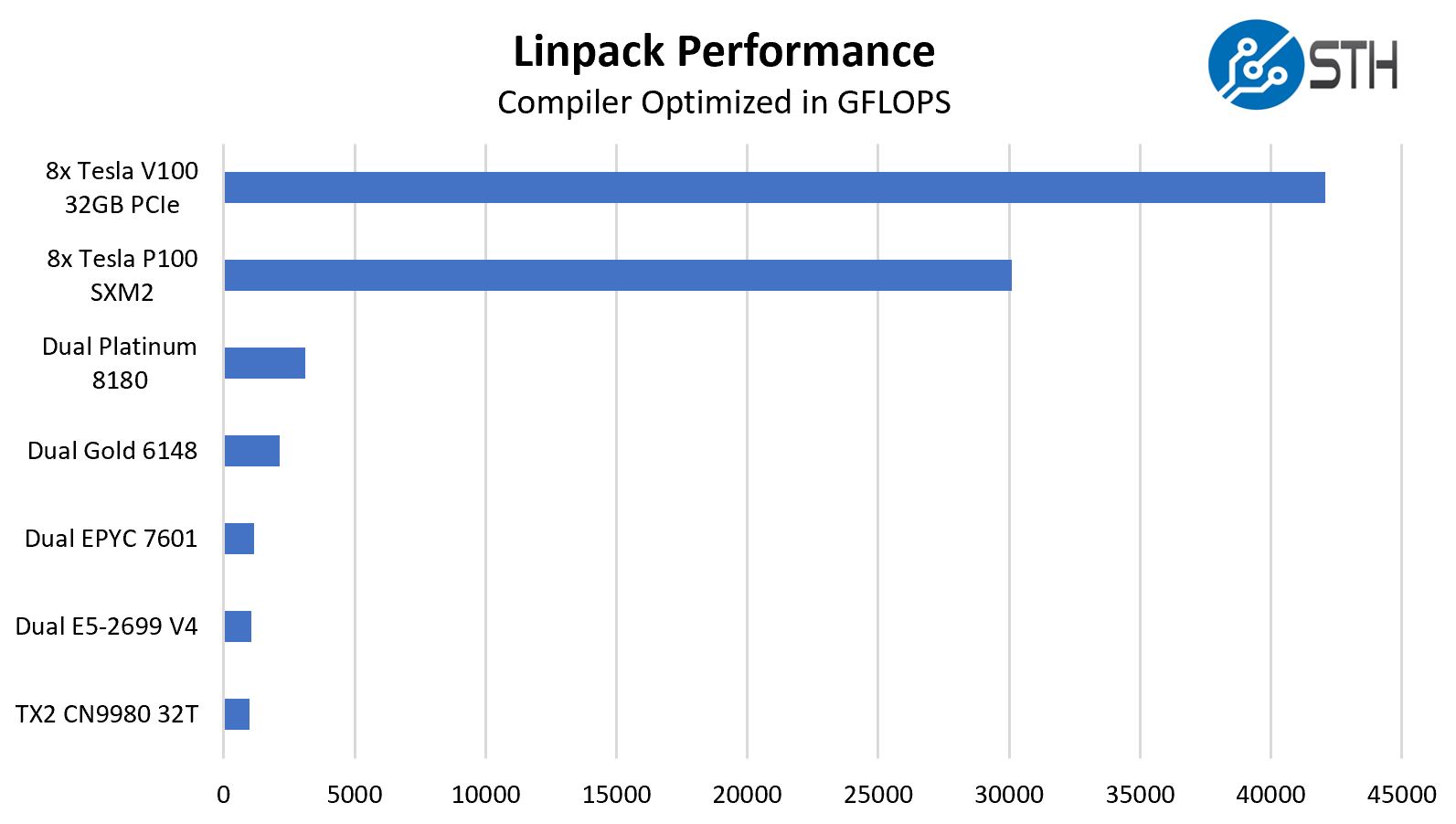
Hpl Performance Comparison 8x Tesla V100 32gb Pcie And Cpus Servethehome
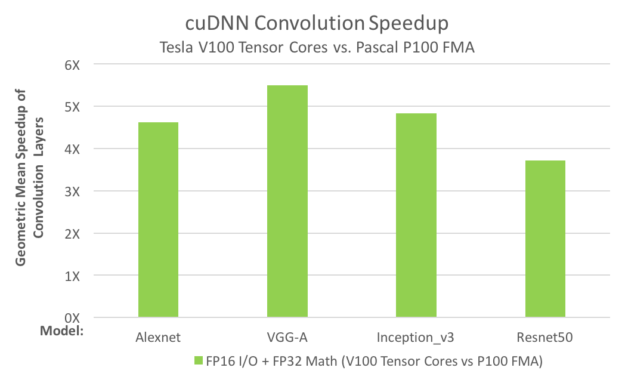
Hardware For Deep Learning Part 3 Gpu By Grigory Sapunov Intento
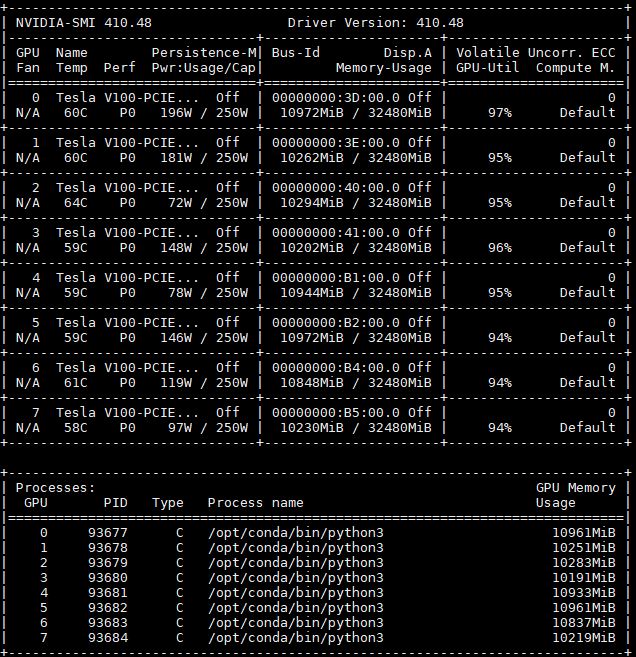
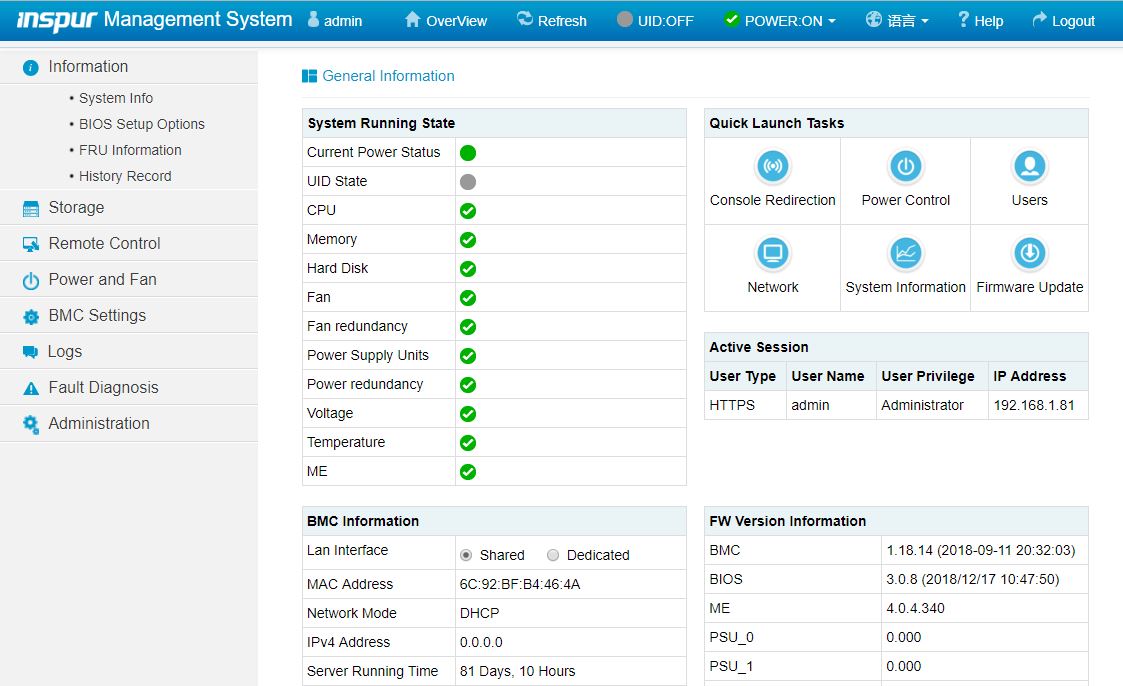
Inspur Systems Nf5468m5 Review 4u 8x Gpu Server Page 5 Of 7 Servethehome

Inspur Nf5488m5 Review A Unique 8x Nvidia Tesla V100 Server
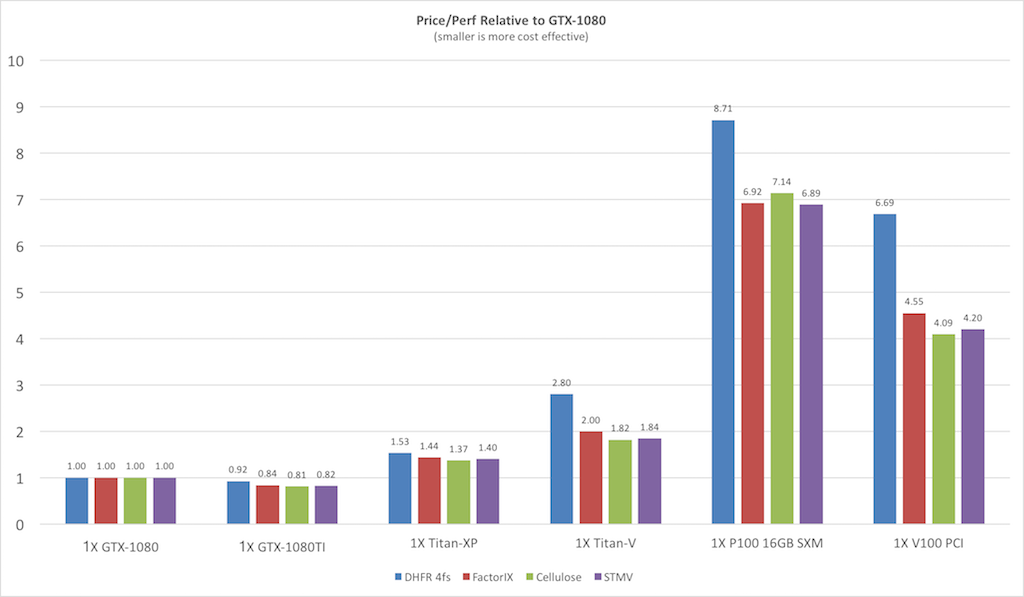
Amber Gpu Benchmarks

Nvidia A100 Ampere Benchmarked The Fastest Gpu Ever Recorded Videocardz Com
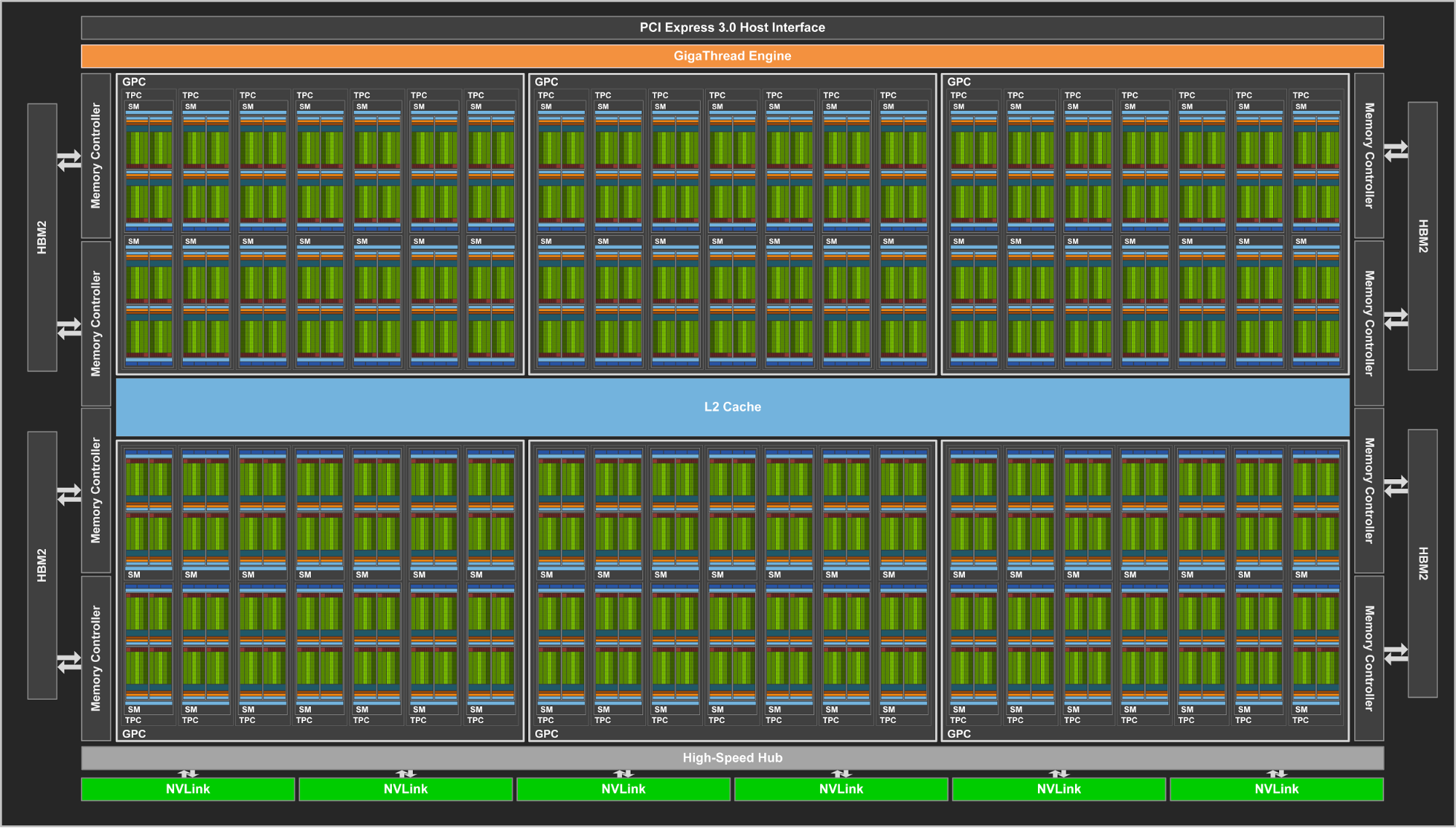
Nvidia Tesla V100 Volta Gpu 16gb Hbm2 900gb Sec Tweaktown

Inspur Systems Nf5468m5 Review 4u 8x Gpu Server Servethehome

